AI를 구현하기 위한 machine learning 알고리즘이 나오기 시작해요.
Neural Networks → 초창기에 나왔어요!
Regression
SVM Decision Trees KNN → 나중에 나왔어요.
Neural(신경세포)을 프로그램 적으로 Modeling

Logistic과 비슷해요. 나중에 Logistic으로 발전~!
사람들은 이런 퍼셉트론을 많이 많이 모아서 AI로 만들 수 있겠다 생각했어요!
컴퓨터는 신호가 들어갔을 때 어떤 신호가 나오느냐는 판단하는 gate 회로들이 모여서 실제 process를 진행해요.
간단하게 보면 컴퓨터가 연산하는 기본적인 단위 gate → 60년대에는 우리가 만든 퍼셉트론 하나가 AND, OR 등
기타 회로를 구성하는 여러 가지 gate를 구성할 수 있으면(사람의 뇌에 해당하는 퍼셉트론을 다 처리할 수 있으면)
생각하는 컴퓨터를 만들어 낼 수 있다고 생각했어요.
회로이론의 기본단위(gate)들을 퍼셉트론으로 구현(Modeling )할 수 있는지를 확인해 보아요!
AND : X로 연산 표현 → 둘 다 1 인 경우만 1
OR : + 로 연산 표현 → 둘 중 하나만 1이면 1
XOR : ⊕로 연산 표현 → 두 개가 다르면 1 두 개가 같으면 0
진리표 어떤 연산이냐라는 것을 보여주는 표
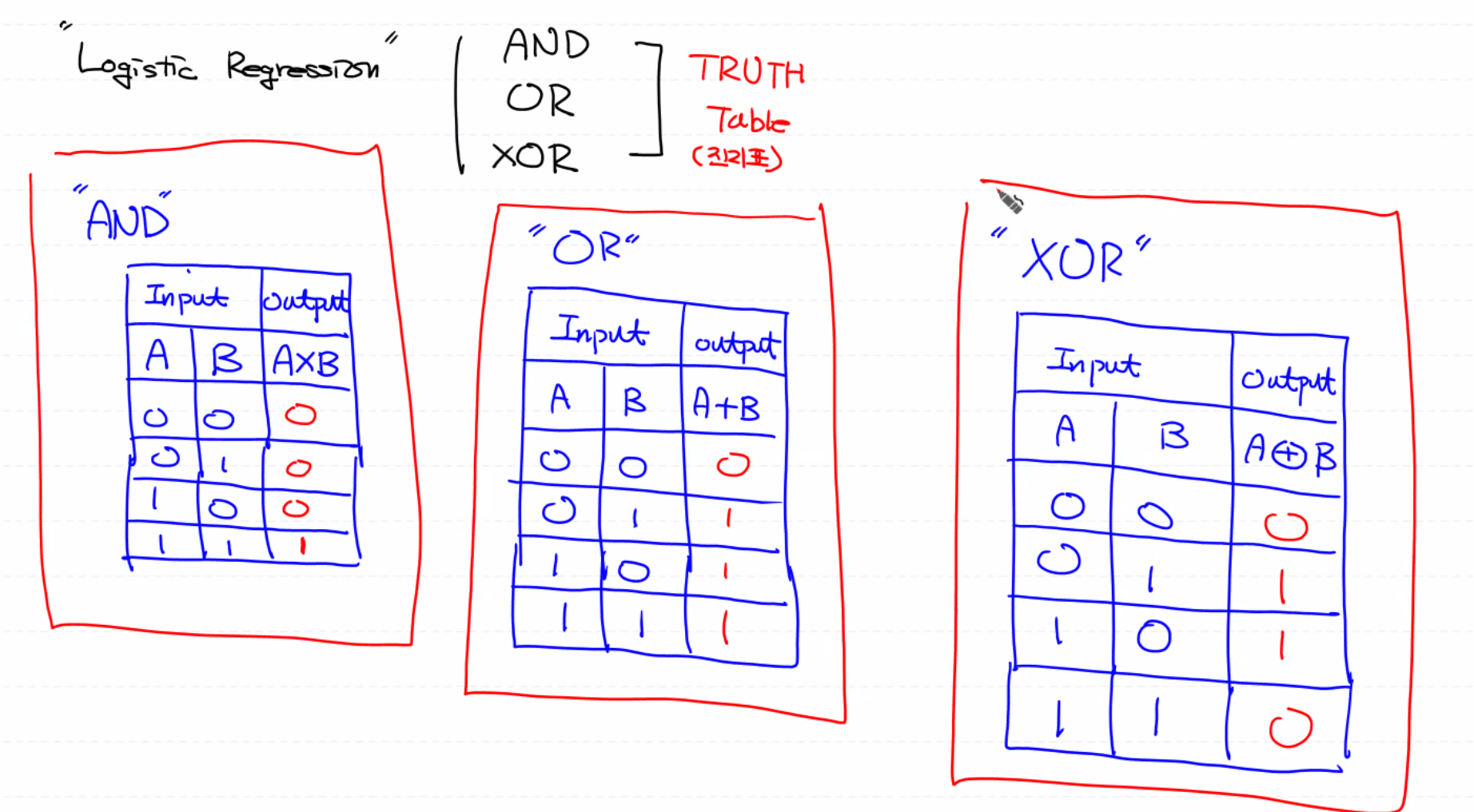
Logistic Regression으로 AND, OR, XOR gate를 구현해 보아요.
Tensorflow 1.15 버전으로 AND, OR, KOR Gate에 대한 진리표를 학습시켜 보아요!
import numpy as np
import tensorflow as tf
from sklearn.metrics import classification_report
# Training Data Set
x_data = np.array([[0,0],
[0,1],
[1,0],
[1,1]], dtype=np.float64)
# AND Gate
# t_data = np.array([[0], [0], [0], [1]], dtype=np.float64)
# OR Gate
# t_data = np.array([[0], [1], [1], [1]], dtype=np.float64)
# XOR Gate
t_data = np.array([[0], [1], [1], [0]], dtype=np.float64)
# placeholder
X = tf.placeholder(shape=[None,2], dtype=tf.float32)
T = tf.placeholder(shape=[None,1], dtype=tf.float32)
# Weight & bias
W = tf.Variable(tf.random.normal([2,1])) # X랑 W와 곱해서 T가 만들어져요. 행렬곱을 위해 shape을 맞춰줘요!
b = tf.Variable(tf.random.normal([1]))
# Hypothesis
logit = tf.matmul(X,W) + b
H = tf.sigmoid(logit)
# loss
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logit,
labels=T))
# train 노드
train = tf.train.GradientDescentOptimizer(learning_rate=1e-2).minimize(loss)
# session, 초기화
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# 학습
for step in range(300000):
tmp, loss_val = sess.run([train, loss], feed_dict={X:x_data,
T:t_data})
if step % 30000 == 0:
print('loss : {}'.format(loss_val))
# evaluation
# cast는 논리 값을 실수로 바꿔주는 역할을 합니다.
acc = tf.cast(H > 0.5, dtype=tf.float32)
result = sess.run(acc, feed_dict={X:x_data})
print(classification_report(t_data.ravel(), result.ravel()))
precision recall f1-score support
0.0 0.33 0.50 0.40 2
1.0 0.00 0.00 0.00 2
accuracy 0.25 4
macro avg 0.17 0.25 0.20 4
weighted avg 0.17 0.25 0.20 4
# AND Gate연산은 Logistic Regression(Perceptron)으로 구현할 수 있어요!!
# OR Gate연산은 Logistic Regression(Perceptron)으로 구현할 수 있어요!!
# XOR Gate연산은 Logistic Regression(Perceptron)으로 구현할 수 없어요!!
XOR은 구현이 되지 않아요.
1969 마빈 민스키(MIT AI Lab 창시자)는 XOR을 학습시키려면 단일 perceptron으로는 불가능하다고 생각했어요.
MLP다층 퍼셉트론(multi-layer perceptron)을 이용하면 가능은 한데,
MLP는 학습이 너무 어려워서 지구상에 있는 누구라도 이 학습을 시킬 수 없다.
수학적으로 불가능하다고 발표했어요.→ Machine Learning의 침체기!!
뉴런이 logistic으로 mapping

Artificial Neural Network(인공신경망)

keras의 구조와 와 닮았어요! 실제로 인공신경망을 Modeling
Deep Learning
Deep Learning은 1개의 logistic regression을 나타내는 node를 서로 연결시켜서 신경망 구조로 만든 것이에요!
→ 일반적으로 입력층(Input Layer) 1개 + 한 개 이상의 은닉층(Hidden Layer) + 출력층(Output Layer) 구성
출력층에서 나오는 오차(예측값과 실제 값의 차이)를 기반으로 각 node가 가지는 가중치(weight, bias)를 학습하는 구조예요. → weight의 개수(복잡도)가 늘어나요.
일반적으로 Deep Learning에서는 은닉층(Hidden Layer)을 1개 이상 사용해서 model의 정확도를 높일 수 있어요!
하지만 layer가 많아지고 node의 수가 많아지면 시간이 오래 걸리고 과대 적합(overfitting) 문제가 생겨요.
Hidden layer를 몇 개 넣을 거냐?? 각 layer에 node를 몇 개 집어넣을 거냐? 판단해야 해요.
Hidden layer 하나가 제일 효율이 좋고 보통 3개 이하로 해요!

Hidden Layer는 임의대로 추가하고 안에 node의 수도 내가 결정해요.
multi layer를 이용해서 XOR(exclusive or) 문제를 학습해 보아요!
→ 독립변수(x)가 2개, w(우리가 구해야 하는 가중치)가 2행 1열(2,1)인 이유는 앞에 x와 행렬곱 연산을 위해,
(2,1)에서 뒤에 1의 의미는 logistic이 한 개 즉 결과로 나가는 게 하나라는 의미예요!

모델이 복잡도를 늘려서 조금 더 정확해지기 위해 layer를 늘리는 거예요!
multi layer를 이용해서 XOR문제를 학습해 보아요!
import numpy as np
import tensorflow as tf
from sklearn.metrics import classification_report
# Training Data Set
x_data = np.array([[0,0], [0,1], [1,0], [1,1]], dtype=np.float64)
t_data = np.array([[0], [1], [1], [0]], dtype=np.float64)
# placeholder
X = tf.placeholder(shape=[None,2], dtype=tf.float32)
T = tf.placeholder(shape=[None,1], dtype=tf.float32)
# Weight & bias
# 그림에서 가운데 hidden layer를 열 개 넣을 거예요!
W1 = tf.Variable(tf.random.normal([2,10]))
b1 = tf.Variable(tf.random.normal([10]))
layer2 = tf.sigmoid(tf.matmul(X,W1) + b1) # 두 번째 layer hidden layer에서 sigmoid 거쳐 나온 결과물
W2 = tf.Variable(tf.random.normal([10,8])) # hidden layer 결괏값은 다음 layer의 input값
# 그 node에 임의로 8개 줘요 8은 의미 없어요 hidden layer2
b2 = tf.Variable(tf.random.normal([8]))
layer3 = tf.sigmoid(tf.matmul(layer2,W2) + b2)# hidden layer2 결괏값은 다음 output layer의 input값
W3 = tf.Variable(tf.random.normal([8,1]))
b3 = tf.Variable(tf.random.normal([1]))
# layer4가 마지막 logit이니까 hyphothesis로 잡아요.
# hypothesis
logit = tf.matmul(layer3,W3) + b3
H = tf.sigmoid(logit)
# loss
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logit,
labels=T))
# train 노드
train = tf.train.GradientDescentOptimizer(learning_rate=1e-2).minimize(loss)
# session, 초기화
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# 학습
for step in range(30000):
tmp, loss_val = sess.run([train, loss], feed_dict={X:x_data,
T:t_data})
if step % 3000 == 0:
print('loss : {}'.format(loss_val))
#loss : 0.02664753422141075
# evaluation
# cast는 논리 값을 실수로 바꿔주는 역할을 합니다.
acc = tf.cast(H > 0.5, dtype=tf.float32)
result = sess.run(acc, feed_dict={X:x_data})
print(classification_report(t_data.ravel(), result.ravel()))
precision recall f1-score support
0.0 1.00 1.00 1.00 2
1.0 1.00 1.00 1.00 2
accuracy 1.00 4
macro avg 1.00 1.00 1.00 4
weighted avg 1.00 1.00 1.00 4
# XOR 연산은 multi layer로 구현은 가능해요
Tensorflow 2.x XOR구현
# Training Data Set (XOR)
x_data = np.array([[0,0], [0,1], [1,0], [1,1]], dtype=np.float64)
t_data = np.array([[0], [1], [1], [0]], dtype=np.float64)
# model
model = Sequential()
# layer추가
# 2x버전에서는 W와 b를 keras가 자동으로 계산해줘요
model.add(Flatten(input_shape=(2,))) # input layer
model.add(Dense(10, activation='sigmoid')) # 첫 번째 hidden layer
model.add(Dense(8, activation='sigmoid')) # 두 번째 hidden layer
model.add(Dense(20, activation='sigmoid')) # 세 번째 hidden layer
model.add(Dense(1, activation='sigmoid')) # output layer # 최종적인 결과는 0이나 1이기에 하나만 잡아요.
# compile
model.compile(optimizer=Adam(learning_rate=1e-2),
loss='binary_crossentropy',
metrics=['acc']) # accuracy
# 학습
# batch는 데이터의 사이즈가 작아 뺐어요!
model.fit(x_data,
t_data,
epochs=30000,
verbose=0)
predict_val = model.predict(x_data)
# print(predict_val) # sigmoid 각각 네게의 확률 값(0,0)(0,1)(1,0)(1,1)
# numpy를 이용하면 해당 tensor의 data만 가지고 올 수 있어요.
# cast : 논리 값을 실수로 바꿔주는 역할을 합니다.
# ravel() → classification_report에 들어가려면 1차원이 돼야 해요.
result = tf.cast(predict_val > 0.5, dtype=tf.float32).numpy().ravel() # 예측 값
# 정답과 예측한 값 비교
print(classification_report(t_data.ravel(), result))
precision recall f1-score support
0.0 1.00 1.00 1.00 2
1.0 1.00 1.00 1.00 2
accuracy 1.00 4
macro avg 1.00 1.00 1.00 4
weighted avg 1.00 1.00 1.00 4
'머신러닝 딥러닝' 카테고리의 다른 글
| 0916 Deep Learning (0) | 2021.09.16 |
|---|---|
| 0915 mnist (0) | 2021.09.16 |
| 0914 MNIST_ keras (0) | 2021.09.14 |
| 0914 titanic_keras (0) | 2021.09.14 |
| 0910 k-nearest Neighbor (KNN) 'K - 최근접 이웃' (0) | 2021.09.10 |



댓글