DecisionTree는 깊이가 작은 경우 매우 잘 작동
→ 하지만 실제 Tree는 깊이가 깊은 경우가 많아, overfitting이발생하기 쉽고 분산이 높아짐
이를 극복하려 훈련 데이터는 무작위로 샘플링(부트스트랩 샘플)
이런 DecisionTree의 집합을 RandomForest 앙상블이라고 함
앙상블 모델의 최종 결과는 전체 앙상블의 편향을 변경하지 않고 분산을 줄여
과반수 투표로 결정됨(Bagging, Bootstrap Aggregation)
GridSearchCV
모든 경우의 수에 대해서 성능 측정
Out Of Bag(OOB)
Out of Bag(OOB) 점수는 Random Forest 모델을 검증하는 방법
이상적인 경우 전체 훈련 데이터의 약 36.8%가 OOB 샘플(학습 데이터)을 형성
나머지 63.2%는 Tree 생성
oob_score=True
→ 학습 데이터 중 일부는 Tree 만들고 일부는 성능 측정

GridSearchCV 파라미터
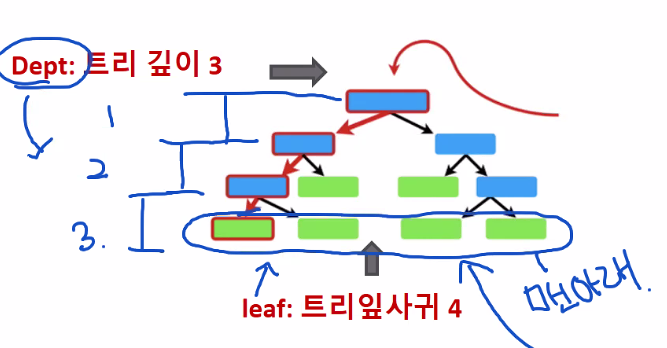
leaf
트리 잎사귀, 트리의 맨 아래 개수
Dept
트리 깊이, 밑으로 분기해서 가지치기한 층수

사진 설명을 입력하세요.
sample split
중복을 제거하고 나온 데이터의 줄의 수
n_jobs
학습을 활용하기 위해 cpu를 n 개 병렬적으로 사용
코어의 개수가 이보다 많다면 그에 맞는 코어의 개수를 적용하면 더욱 성능 향상
ex)RandomForestClassifier() Tree가 100개라고 가정
n_jobs = None
0번째 트리 예측 → 1번째 → 2번째 → 3번째 ''''' → 100번째
n_jobs = None → 한 번에 트리 하나씩 순서대로 예측 → 시간이 오래 걸려요 ..
n_jobs =10
cpu 일정 영역 10개로 나눔 → 10개 동시 예측
'머신러닝 딥러닝' 카테고리의 다른 글
| AUC-ROC 커브 (0) | 2022.01.20 |
|---|---|
| 0119 Ensenble, XGBoost (0) | 2022.01.19 |
| 0118 confusion matrix( 오차 행렬), Information Gain(IG) (0) | 2022.01.18 |
| 0117 Random Forest (0) | 2022.01.17 |
| 0114 Decision Tree (0) | 2022.01.14 |



댓글