• Sparse Representation (희소 표현)
- 벡터, 행렬의 값이 대부분이 0으로 표현
- ex) one-hot-vector
- ex) 강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0]
• Dense Representation (밀집 벡터)
- 사용자가 설정한 값으로 모든 단어의 벡터 차원을 맞춤
- 실수로 표현
- ex) 강아지 = [0.2 1.8 1.1 -2.1 1.1 2.8 ... ] # 이 벡터의 차원은 128
• 희소 표현으로는 유사성 표현할 수 없음 → 다차원 공간에 벡터화
• 단어 간 유사성을 벡터화. → 워드 임베딩
• 단어를 벡터로 표현 → 밀집 표현
- Embedding Vector
- LSA, Word2Vec, FastText, Glove, Keras의 Embedding()
Word2Vec
단어 벡터 간 유사도 반영 → 단어를 수치화
Word2Vec 테스트 사이트[Korean Word2Vec]
• CROW(Continuous Bag of Words)
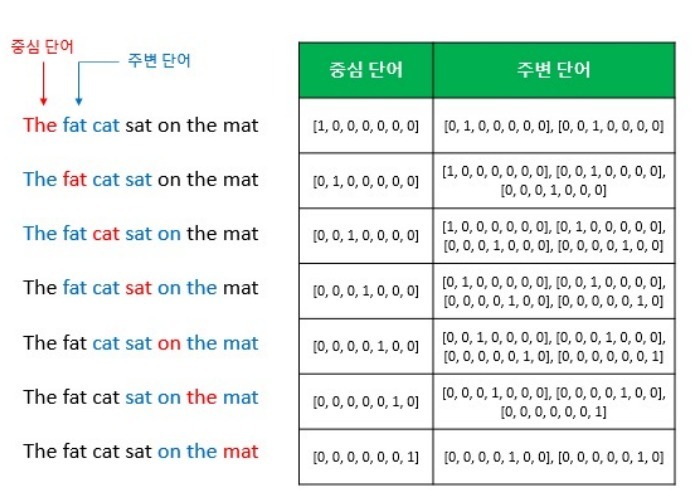
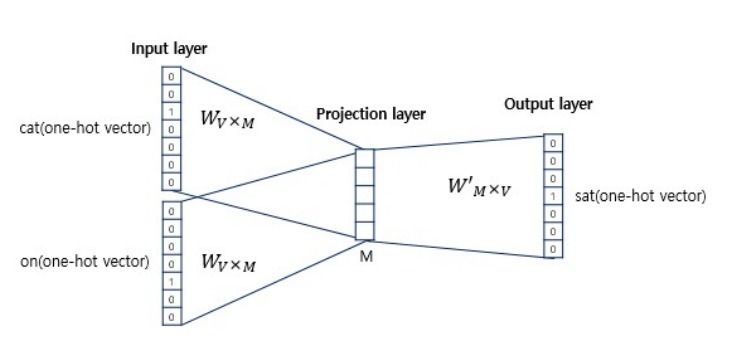
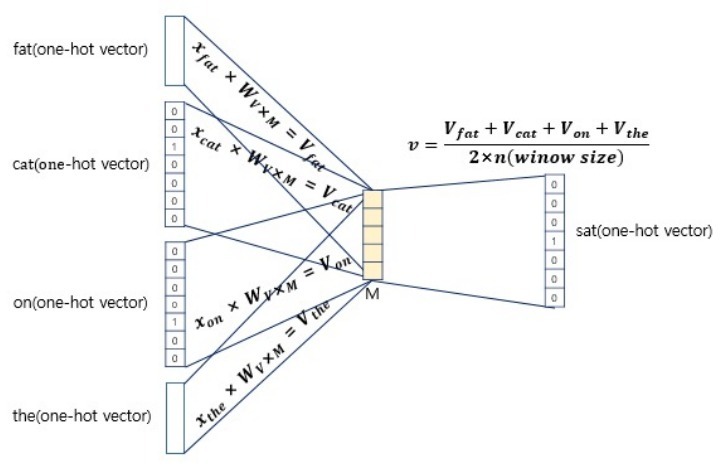
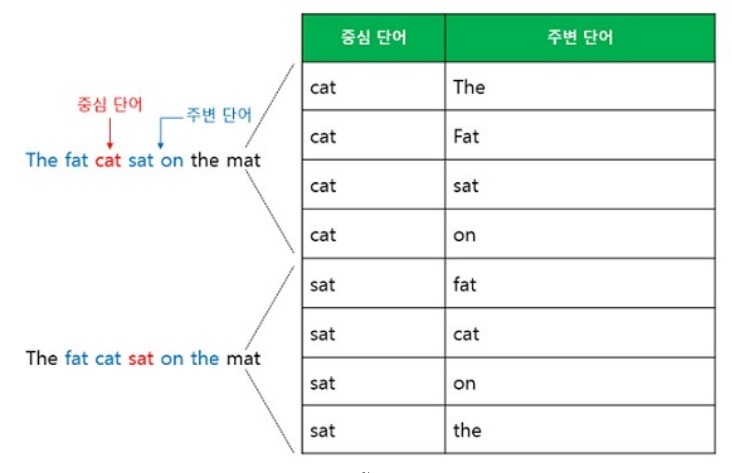
• Skip-Gram
- 중간의 단어로 주변 단어를 예측

Vector란??
• 비슷한 특징 (Sementics)를 갖는 단어를 추측
-시멘틱스 (Sementics, 의미) - 프로그램이 무엇을 어떻게 수행할지 나타내 주며, 특정 기능의 의미가 다 른 부분
과의 상호 연관에 의해서만 정확히 설명
• 다음에 올 단어를 추측
- 번역
- 자동 문장 생성, 자동 응답 → AI System
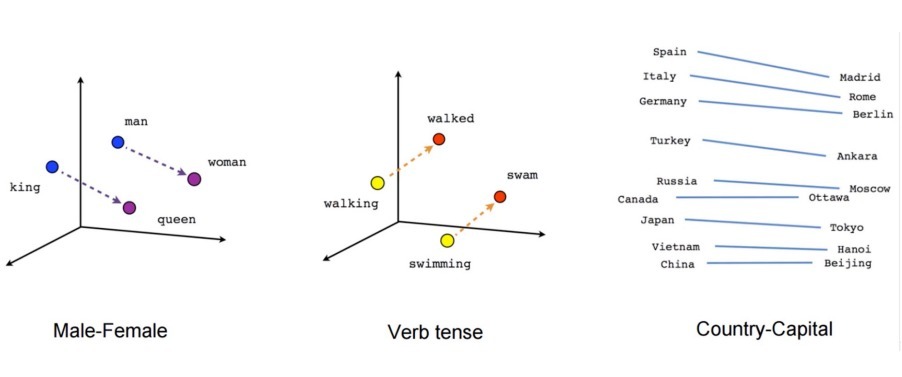
단어 가지고 백터 표현 그림[Linguistic Regularities in Continuous Space Word Representations - ACL Anthology]
'자연어처리(NLP)' 카테고리의 다른 글
| Tokenization (0) | 2022.03.22 |
|---|---|
| 베이즈 정리(Bayes’ theorem) (0) | 2022.03.21 |
| Python Text, PDF파일 다루기 (0) | 2022.03.15 |
| 정규표현식(Regular Expression) (0) | 2022.03.15 |




댓글